
El machine learning ya no observa la realidad, la interpreta y actúa sobre ella. Sistemas que aprenden de la experiencia, ajustan su comportamiento y toman decisiones sin intervención humana directa forman parte de su funcionamiento normal, aunque muchas veces pase desapercibido.
Dentro del ecosistema del Big Data, el machine learning convierte grandes volúmenes de información en modelos capaces de detectar patrones, anticipar escenarios y evolucionar con cada nuevo dato. Entender cómo aprende una máquina, qué tipos de modelos existen y qué perfiles profesionales trabajan con estas tecnologías resulta clave para comprender por qué esta disciplina se ha convertido en uno de los pilares de la transformación digital.
¿Quieres descubrir más sobre el machine learning?
Cómo surge, cuáles son sus aplicaciones reales y por qué es imprescindible entender sus usos más comunes ya no son preguntas teóricas. Esta disciplina forma parte del día a día, a veces de manera invisible y otras de forma evidente, integrada en sistemas que aprenden, recomiendan, predicen y automatizan decisiones sin que el usuario sea plenamente consciente de ello.
Este protagonismo explica por qué el machine learning es en una de las competencias más demandadas en el ámbito tecnológico. El crecimiento acelerado de soluciones basadas en Inteligencia Artificial impulsa la necesidad de perfiles capaces de comprender, desarrollar e interpretar estos modelos, situando el conocimiento en ML como un elemento central para entender cómo funciona la tecnología actual.
El machine learning interpreta datos, aprende de la experiencia y actúa dentro del ecosistema del Big Data, convirtiéndose en una pieza clave para entender cómo los sistemas detectan patrones y toman decisiones en la transformación digital
¿Quién definió el concepto de ML?
El concepto de machine learning surge en la segunda mitad del siglo XX, en un contexto marcado por la necesidad de que las máquinas fueran más allá de ejecutar instrucciones rígidas. La idea central consistía en crear sistemas capaces de aprender de la experiencia y mejorar su rendimiento a medida que procesaban nueva información, sin necesidad de reescribir constantemente su código.
El término se atribuye a Arthur Samuel, investigador pionero que definió el ML como la capacidad de los ordenadores para aprender sin ser programados explícitamente para cada tarea. Su trabajo demostró que una máquina podía ajustar su comportamiento a partir de datos previos, sentando las bases de una disciplina que hoy resulta esencial para entender la Inteligencia Artificial moderna.
Desde entonces, el machine learning ha evolucionado de un planteamiento experimental a una tecnología clave en entornos reales. Lo que comenzó como una idea teórica orientada a juegos y problemas acotados se ha convertido en un conjunto de técnicas capaces de analizar grandes volúmenes de datos, identificar patrones complejos y tomar decisiones adaptativas en contextos dinámicos. Esta evolución explica por qué el concepto, definido hace décadas, sigue siendo plenamente vigente en la actualidad.
¿Cómo aprende una máquina a partir de los datos?
El machine learning se basa en un principio sencillo en apariencia, pero potente en la práctica porque una máquina aprende cuando analiza datos y extrae patrones a partir de ellos. En lugar de recibir instrucciones detalladas para cada situación, el sistema utiliza ejemplos previos para ajustar su comportamiento y generar respuestas coherentes ante nuevos casos.
Este aprendizaje comienza con un conjunto de datos que actúa como referencia. A partir de ahí, el modelo identifica regularidades, relaciones y tendencias que le permiten generalizar más allá de los ejemplos iniciales. El proceso no consiste en memorizar información, sino en construir una representación interna que facilite la toma de decisiones cuando aparecen datos que no había visto antes.
A medida que el sistema incorpora nueva información, el modelo se ajusta y refina. Este mecanismo explica por qué el rendimiento mejora con el tiempo y por qué la calidad de los datos resulta determinante. Si los datos son incompletos, sesgados o poco representativos, el aprendizaje se resiente. Si, por el contrario, reflejan correctamente la realidad, el modelo adquiere mayor capacidad para interpretar situaciones futuras con precisión.
¿Cuáles son los 3 tipos de machine learning?
El machine learning se organiza en tres enfoques principales, definidos por la forma en que el modelo aprende y por el tipo de información que utiliza. Cada uno responde a problemas distintos y se aplica en contextos específicos.
- Aprendizaje supervisado: El modelo aprende a partir de datos etiquetados, donde cada ejemplo incluye el resultado esperado. A partir de esa referencia, ajusta sus predicciones de forma progresiva y mejora su precisión con el entrenamiento.
- Aprendizaje no supervisado: El sistema trabaja con datos sin etiquetar y se centra en identificar patrones, estructuras o agrupaciones internas. Este enfoque es clave para exploración de datos, segmentación y descubrimiento de relaciones no evidentes.
- Aprendizaje por refuerzo: El modelo aprende mediante la interacción con un entorno, evaluando las consecuencias de sus acciones. A través de recompensas y penalizaciones, ajusta su estrategia para optimizar resultados a lo largo del tiempo.
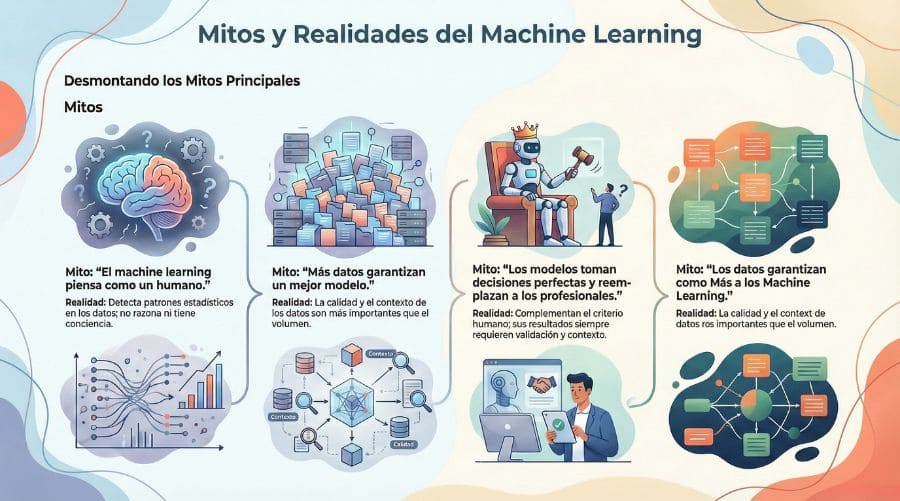
Mitos frecuentes sobre machine learning
El ML arrastra una serie de ideas simplificadas que generan expectativas poco realistas sobre su funcionamiento y su alcance.
- Mito 1. Machine learning piensa o razona como una persona: Los modelos no comprenden ni interpretan la realidad, sino que detectan patrones estadísticos a partir de datos. No existe conciencia, intención ni criterio propio detrás de sus resultados.
- Mito 2. Más datos garantizan mejores modelos: El volumen de información no asegura buenos resultados si los datos son incompletos, sesgados o poco representativos. La calidad y el contexto del dato condicionan directamente el aprendizaje.
- Mito 3. Los modelos toman decisiones perfectas: Machine learning aprende del pasado y reproduce patrones existentes, incluidos errores y sesgos. Por este motivo, sus resultados siempre deben analizarse y validarse.
- Mito 4. Cualquiera puede aplicar machine learning sin formación: Aunque existen herramientas que facilitan su uso, interpretar modelos, evaluar resultados y entender sus límites requiere conocimientos sólidos en análisis de datos y negocio.
- Mito 5. El machine learning sustituye al profesional: Estos sistemas no reemplazan el criterio humano, sino que lo complementan. El valor real surge cuando existe capacidad para interpretar los modelos, contextualizar los resultados y tomar decisiones informadas a partir de ellos.
Comprender estos límites marca la diferencia entre usar machine learning de manera superficial o aplicarlo con criterio en entornos reales, una distinción que se trabaja de manera estructurada en el Máster en Big Data & Business Intelligence, donde la tecnología se aborda desde una perspectiva práctica, crítica y orientada a negocio.