
La minería de datos avanzada con Open Source es una ventaja técnica real cuando el volumen, la variedad y la velocidad del dato obligan a ir más allá del análisis clásico. El valor surge al combinar estadística, aprendizaje automático e Inteligencia Artificial para descubrir patrones, anticipar tendencias y detectar relaciones ocultas en conjuntos de datos complejos.
Este enfoque encaja con entornos donde conviven datos estructurados, semiestructurados y no estructurados, y donde es crítico escalar el procesamiento sin perder control metodológico. El Open Source refuerza la transparencia del ciclo analítico, desde la preparación del dato hasta la evaluación del modelo, y facilita una mejora continua basada en validación, iteración y aprendizaje riguroso.
Bases de datos Open Source
Las bases de datos Open Source actúan como el núcleo operativo de los proyectos de minería de datos avanzada, ya que permiten almacenar, gestionar y preparar grandes volúmenes de información con un alto grado de control técnico. Su código abierto facilita la adaptación a distintos contextos analíticos y garantiza que los modelos de datos evolucionen al mismo ritmo que las necesidades del proyecto. Esta flexibilidad es importante cuando se trabaja con arquitecturas analíticas complejas que integran múltiples fuentes y formatos de información.
Además, estas bases de datos destacan por su capacidad de integrarse con lenguajes y herramientas propias del ecosistema Open Source, lo que simplifica la construcción de pipelines analíticos completos. La interoperabilidad con entornos de análisis estadístico, minería de datos y visualización refuerza su papel dentro de arquitecturas de Big Data escalables. A esto se suma una comunidad técnica activa que impulsa mejoras constantes, corrige vulnerabilidades y amplía funcionalidades, consolidando un entorno fiable y preparado para proyectos de análisis avanzado exigentes.
La minería de datos avanzada con Open Source aporta valor real al combinar estadística, aprendizaje automático e Inteligencia Artificial para analizar grandes volúmenes de datos y descubrir patrones y tendencias ocultas
Ventajas de usar bases de datos Open Source en proyectos de análisis
El uso de bases de datos Open Source aporta una ventaja estructural en proyectos de análisis avanzado al eliminar dependencias tecnológicas rígidas. Al trabajar con código abierto, los equipos mantienen control total sobre la arquitectura de datos, lo que facilita adaptar esquemas, optimizar consultas y ajustar el rendimiento según la naturaleza del análisis. Esta capacidad es importante cuando los modelos evolucionan y exigen cambios frecuentes en la forma de almacenar y acceder a la información.
Otro factor determinante es la eficiencia económica vinculada al Open Source. La ausencia de licencias propietarias libera recursos que se destinan a infraestructura, talento o mejora de modelos analíticos. Este enfoque favorece la experimentación continua y reduce las barreras de entrada para escalar proyectos de minería de datos, incluso en entornos con grandes volúmenes de información o necesidades computacionales crecientes. La inversión se orienta al valor analítico y no al coste del software.
La interoperabilidad constituye otra ventaja clave. Las bases de datos Open Source se integran de manera nativa con lenguajes y librerías de análisis como Python o R, permitiendo construir flujos de trabajo coherentes desde la ingesta del dato hasta la modelización estadística. Esta integración reduce fricciones técnicas y mejora la trazabilidad del análisis, algo esencial cuando se requiere reproducibilidad y validación rigurosa de resultados.
Finalmente, la transparencia del código refuerza la seguridad y la calidad del dato. La revisión continua por parte de comunidades técnicas facilita la detección temprana de errores y vulnerabilidades, al tiempo que acelera la incorporación de mejoras funcionales. En proyectos de análisis avanzado, donde la fiabilidad del dato condiciona directamente la calidad del modelo, esta combinación de control, adaptación y evolución constante sitúa a las bases de datos Open Source como un componente estratégico.

Software de minería de datos ¿Qué hay de Weka?
Weka es una de las herramientas Open Source más utilizadas en minería de datos por su enfoque práctico y su orientación didáctica sin perder rigor técnico. Desarrollado en el entorno académico, integra en un único framework algoritmos de clasificación, regresión, clustering y asociación que permiten abordar problemas analíticos completos desde la exploración inicial hasta la validación del modelo. Su arquitectura basada en Java garantiza portabilidad y estabilidad en distintos sistemas, algo especialmente valioso en entornos formativos y de investigación aplicada.
Uno de los rasgos diferenciales de Weka es su interfaz gráfica, que permite trabajar con modelos de aprendizaje automático sin necesidad de programar. Esta característica acelera la comprensión de los algoritmos y facilita la experimentación controlada con distintos enfoques analíticos. Al mismo tiempo, Weka ofrece una API que habilita su integración en flujos más complejos, lo que permite combinar su potencia algorítmica con otros lenguajes y plataformas del ecosistema Open Source.
El preprocesamiento del dato ocupa un papel central dentro de Weka. La herramienta incorpora funciones específicas para limpieza, selección de atributos y transformación de variables, aspectos determinantes para mejorar la calidad del modelo. Esta etapa es crítica en proyectos reales, donde la calidad del dato condiciona directamente la capacidad predictiva y la estabilidad de los resultados.
En la fase de evaluación, Weka proporciona métricas sólidas y procedimientos de validación que permiten analizar el comportamiento real de los modelos y evitar problemas como el sobreajuste. Este enfoque metodológico refuerza su utilidad como entorno de minería de datos avanzada, especialmente cuando el objetivo es comprender el funcionamiento interno de los algoritmos y no solo obtener predicciones finales.
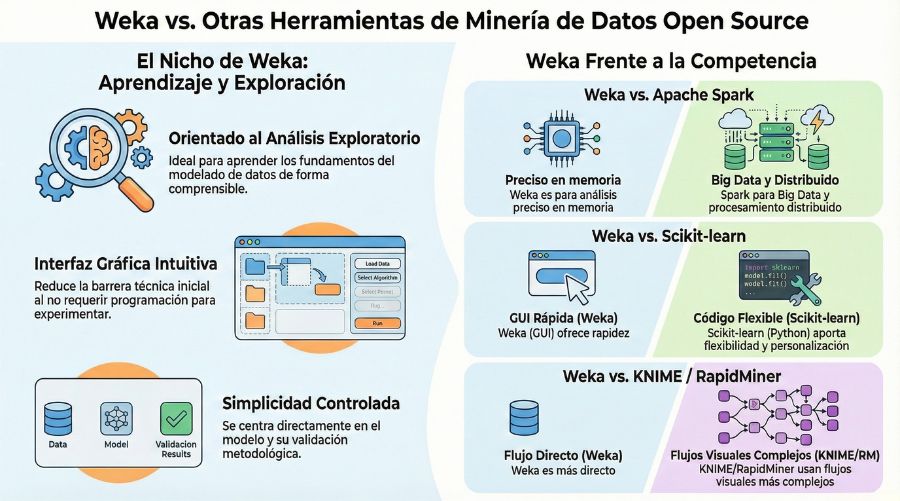
Comparativa de Weka con otras herramientas Open Source
La comparación de Weka con otras herramientas Open Source permite entender mejor su encaje dentro de proyectos de minería de datos avanzada. Weka destaca por su orientación al análisis exploratorio y al aprendizaje de los fundamentos del modelado, ofreciendo un entorno controlado donde los algoritmos se aplican directamente. Esta característica lo diferencia de plataformas pensadas para entornos distribuidos, donde la complejidad técnica prioriza la escalabilidad sobre la interpretación detallada del modelo.
Frente a frameworks como Apache Spark, Weka se posiciona como una solución más ligera y centrada en conjuntos de datos manejables en memoria. Spark responde mejor a escenarios de datos masivos y procesamiento distribuido, mientras que Weka permite analizar con mayor precisión el impacto de cada variable y parámetro en el resultado final. Esta diferencia marca el tipo de proyecto al que se orienta cada herramienta, más pedagógico y analítico en el caso de Weka, más industrial y escalable en el caso de Spark.
Si se compara con librerías como Scikit-learn, la diferencia principal radica en el enfoque de uso. Scikit-learn exige programación y un dominio mayor del entorno Python, lo que aporta flexibilidad y personalización extrema. Weka, en cambio, reduce la barrera técnica inicial gracias a su interfaz gráfica, facilitando la experimentación rápida y la comprensión del comportamiento de los algoritmos sin necesidad de escribir código.
Otras plataformas como KNIME o RapidMiner incorporan flujos visuales más complejos y orientados a procesos completos de análisis. En este contexto, Weka mantiene una propuesta más directa, centrada en el modelo y en la validación metodológica. Esta simplicidad controlada convierte a Weka en una herramienta especialmente adecuada para comprender la lógica interna de la minería de datos Open Source y sentar bases sólidas antes de escalar hacia arquitecturas analíticas más complejas.
Modelos estadísticos aplicados con Python
Los modelos estadísticos aplicados con Python ocupan un lugar central en la minería de datos Open Source al ofrecer un entorno coherente para analizar, validar y desplegar modelos con rigor matemático. Python integra bibliotecas especializadas que permiten trabajar desde la exploración inicial del dato hasta la inferencia estadística avanzada, manteniendo trazabilidad y control en cada fase del proceso analítico. Este enfoque es necesario cuando el objetivo consiste en entender relaciones reales entre variables y no limitarse a obtener resultados numéricos aislados.
Las técnicas de regresión, tanto lineales como logísticas, permiten modelar relaciones y clasificar observaciones con una base estadística sólida. A través de librerías específicas, el analista evalúa cada variable, interpreta coeficientes y contrasta hipótesis, lo que refuerza la fiabilidad del modelo. Este tipo de análisis es fundamental en contextos donde la interpretación es tan importante como la predicción.
El análisis de series temporales amplía estas capacidades al introducir la dimensión temporal en el modelado. Python facilita la identificación de tendencias, estacionalidades y patrones recurrentes, anticipando comportamientos futuros a partir de datos históricos. Esta aproximación se integra de manera natural en proyectos donde la evolución del dato en el tiempo condiciona la toma de decisiones analíticas.
Los modelos de clasificación y agrupamiento refuerzan el análisis exploratorio y predictivo al segmentar datos según similitudes reales. La validación cruzada y la evaluación mediante métricas estadísticas aseguran que los modelos generalizan correctamente y mantienen estabilidad frente a nuevos datos. En conjunto, Python es una pieza clave en la minería de datos Open Source al unir potencia estadística, reproducibilidad y un ecosistema abierto preparado para proyectos analíticos avanzados.
Tendencias actuales en minería de datos con herramientas Open Source
Las tendencias actuales en minería de datos con herramientas Open Source reflejan una evolución clara hacia entornos más integrados, automatizados y orientados a la escalabilidad analítica. El uso combinado de librerías estadísticas, frameworks de aprendizaje automático y arquitecturas distribuidas permite abordar proyectos cada vez más complejos sin renunciar a la transparencia del modelo. Esta convergencia técnica refuerza la capacidad de analizar datos heterogéneos y de repetir modelos con rapidez y control metodológico.
El protagonismo de Python dentro del ecosistema Open Source se mantiene gracias a su capacidad para actuar como lenguaje integrador. La conexión fluida entre análisis estadístico, minería de datos y visualización facilita ciclos analíticos completos, donde la exploración, el modelado y la validación forman parte de un mismo flujo coherente. A esto se suma la incorporación progresiva de técnicas de Inteligencia Artificial que elevan la capacidad predictiva y permiten detectar patrones no evidentes mediante enfoques tradicionales.
Otra tendencia relevante es la automatización de procesos analíticos. La orquestación de tareas y la estandarización de pipelines permiten reducir errores operativos y garantizar reproducibilidad, un aspecto crítico en proyectos avanzados. Este enfoque favorece entornos donde el análisis deja de ser puntual y pasa a integrarse como un proceso continuo de mejora y aprendizaje.
En este contexto, dominar la minería de datos avanzada con Open Source exige una formación que combine base estadística, conocimiento de herramientas y visión aplicada. Este enfoque integral se desarrolla de manera transversal en el Máster en Big Data y Business Intelligence, donde el Open Source, la analítica avanzada y la IA se trabajan desde una perspectiva técnica y aplicada, orientada a proyectos reales y a la evolución profesional en entornos data driven.