
Apache Kafka es una plataforma distribuida diseñada para la transmisión de datos en tiempo real. Su arquitectura tolerante a fallos y altamente escalable lo convierte en un motor confiable capaz de manejar millones de eventos por segundo sin comprometer la consistencia. Gracias a su log distribuido y a la replicación, se asegura la durabilidad de los mensajes y la continuidad del servicio incluso en escenarios de alta demanda o fallos de hardware.
El verdadero salto ocurre al integrarlo con algoritmos de Machine Learning, que convierten los datos transmitidos en predicciones y acciones automáticas. Este binomio permite optimizar procesos productivos, detectar anomalías en cuestión de segundos y personalizar servicios con precisión. Kafka asegura la ingesta continua y ordenada de la información, mientras que ML descubre patrones ocultos y genera valor estratégico. Juntos conforman una arquitectura inteligente que no solo gestiona información, sino que la transforma en una ventaja competitiva sostenible.
Optimización de producción en Apache Kafka
La optimización en producción con Apache Kafka exige una visión integral que va desde el diseño inicial hasta la operación continua. Todo arranca con la planificación del clúster. Dimensionar correctamente el número de brokers, particiones y réplicas asegura equilibrio en la carga de trabajo y resiliencia frente a caídas. La configuración de parámetros críticos como acks, batch.size, linger.ms o compression.type determina cómo se gestionan los mensajes y cómo se equilibra el binomio rendimiento-latencia. Una arquitectura bien diseñada evita sobrecarga en productores y consumidores, y establece políticas claras de retención de datos para garantizar que los mensajes permanezcan el tiempo necesario sin saturar el almacenamiento.
La monitorización es otro pilar fundamental. Métricas como el lag de los grupos de consumidores, el throughput por partición o la latencia de replicación permiten anticipar problemas antes de que afecten a la operación. Herramientas como Prometheus, Grafana o Confluent Control Center facilitan la visualización y el análisis de estos indicadores en tiempo real. A esto se suma la importancia de contar con discos rápidos, redes de baja latencia y políticas de segmentación de logs que optimicen el acceso a los datos.
Además, la automatización de despliegues con Kubernetes o Ansible asegura consistencia y reproducibilidad en entornos complejos. La validación con pruebas de carga, la introducción de canarios y la simulación de fallos mediante prácticas de caos engineering refuerzan la resiliencia del sistema. Por último, la integración de Machine Learning lleva la optimización a un nuevo nivel a través de modelos entrenados con históricos de tráfico que permiten ajustar dinámicamente la asignación de particiones, predecir picos de demanda y distribuir cargas de forma inteligente. Así, Apache Kafka es un ecosistema proactivo, capaz de sostener operaciones críticas con máxima eficiencia y estabilidad.
Kafka garantiza el flujo continuo y ordenado de datos, mientras que ML detecta patrones ocultos y aporta valor estratégico. Ambos forman una arquitectura inteligente que convierte la información en ventaja competitiva
Rendimiento vs. latencia en Kafka
Rendimiento y latencia representan dos fuerzas en tensión dentro de Apache Kafka. Por un lado, el rendimiento mide la capacidad del sistema para procesar millones de mensajes por segundo de forma sostenida. Por otro, la latencia refleja el tiempo que tarda un mensaje en viajar desde el productor hasta el consumidor. Ajustar ambos factores es clave para que la plataforma entregue valor real en entornos productivos.
Un aumento de rendimiento suele lograrse ampliando el tamaño de los lotes (batch.size), habilitando la compresión de mensajes o relajando el nivel de confirmación (acks). Estas configuraciones reducen el coste por operación, pero incrementan el riesgo de retrasos en la entrega. En cambio, priorizar la baja latencia requiere ajustes como disminuir linger.ms, activar acks=all o reservar particiones exclusivas para flujos críticos. El resultado es una respuesta casi inmediata, aunque a costa de mayores recursos de CPU y memoria.
La estrategia más eficiente es segmentar los casos de uso. Por ejemplo, una aplicación de pagos en línea necesita latencias de milisegundos y debe sacrificar throughput para garantizar consistencia absoluta. En cambio, un sistema de análisis de logs puede tolerar segundos de retraso a cambio de procesar grandes volúmenes con menos costes. Kafka permite diseñar arquitecturas híbridas donde conviven ambos escenarios, asignando configuraciones diferentes a cada topic según su criticidad.
La llegada de Machine Learning añade un nivel adicional de optimización. Con modelos entrenados en métricas históricas, es posible predecir cuándo la latencia puede dispararse y ajustar dinámicamente los parámetros de los productores o brokers. Así, se asegura un equilibrio constante entre rendimiento y tiempos de respuesta, manteniendo la fiabilidad del sistema en condiciones cambiantes.
Modelo de consumo en Apache Kafka
El modelo de consumo en Apache Kafka está basado en grupos de consumidores que se suscriben a los topics. Cada partición de un topic se asigna de forma exclusiva a un consumidor dentro del grupo, lo que permite procesar los mensajes en paralelo y evitar duplicidades. Este esquema facilita la escalabilidad horizontal, ya que al añadir nuevos consumidores el sistema redistribuye automáticamente las particiones.
La gestión de los offsets asegura que cada consumidor conoce el punto exacto por el que va en el log, lo que garantiza consistencia y permite retomar el procesamiento tras un fallo o reinicio. Además, Kafka admite varios grupos de consumidores leyendo un mismo topic sin interferir entre ellos, lo que habilita arquitecturas flexibles donde distintas aplicaciones extraen información de la misma fuente.
¿Kafka es un sistema de empuje o de atracción?
Apache Kafka es un modelo de atracción (pull), no de empuje. Esto significa que los consumidores son los que solicitan los mensajes al broker en lugar de recibirlos automáticamente. Esta decisión de diseño es clave porque ofrece control total al consumidor sobre la velocidad de lectura y evita la sobrecarga que se produce en sistemas de empuje, donde el servidor envía datos aunque el cliente no pueda procesarlos a tiempo.
El enfoque pull asegura que cada aplicación adapte el ritmo de consumo a sus propios recursos, ajustando la concurrencia de hilos o la capacidad de procesamiento. Además, otorga resiliencia. Si un consumidor falla o se reinicia, basta con reanudar desde el último offset almacenado para continuar sin pérdidas ni duplicaciones. Esta característica es esencial en flujos críticos como transacciones financieras, detección de fraude o monitorización de infraestructuras IoT.
Comparado con arquitecturas de empuje, Kafka también aporta previsibilidad. En un sistema push, un pico inesperado de mensajes puede saturar la red o colapsar a los consumidores. En cambio, con pull, los clientes regulan el tráfico que aceptan y procesan, manteniendo estable todo el ecosistema. Esta estabilidad se refuerza con mecanismos de backpressure, que permiten ralentizar el flujo sin comprometer la integridad de los datos.
Otra ventaja es la posibilidad de implementar diferentes patrones de consumo sobre la misma base. Un consumidor puede leer en tiempo real, mientras otro lo hace de manera diferida para análisis históricos, sin que el broker tenga que modificar su comportamiento. Esto convierte a Kafka en una solución flexible, capaz de adaptarse a entornos con requerimientos heterogéneos.
En definitiva, el modelo de atracción de Apache Kafka no solo protege a los consumidores de la sobrecarga, sino que garantiza un equilibrio dinámico entre velocidad, confiabilidad y flexibilidad operativa.
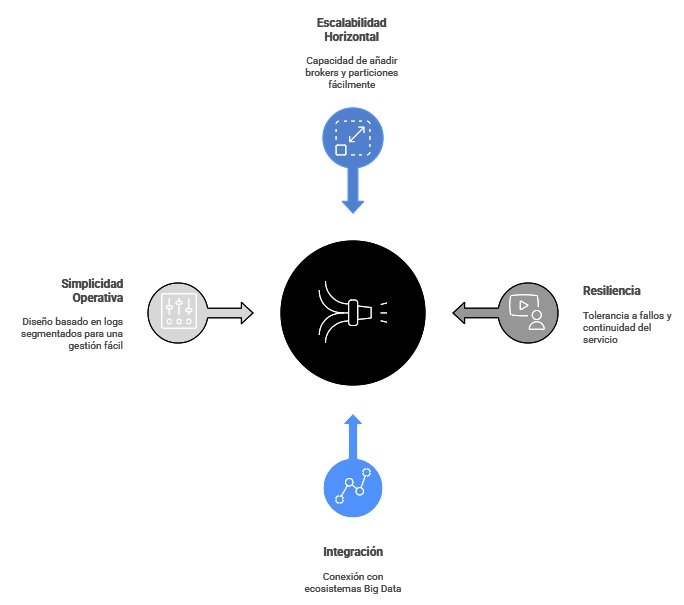
Ventajas de su arquitectura en comparación con otros sistemas
La arquitectura distribuida de Apache Kafka lo diferencia claramente de sistemas de mensajería tradicionales como RabbitMQ o ActiveMQ. Su base en un log commit distribuido asegura que los mensajes se almacenen de forma persistente y puedan ser consumidos varias veces, lo que combina lo mejor de una cola de mensajería con un sistema de almacenamiento. Esta característica permite tanto el consumo en tiempo real como la relectura de históricos para análisis posteriores, algo poco común en otras plataformas.
Otra ventaja es la escalabilidad horizontal. Kafka permite añadir brokers y particiones sin necesidad de reconfiguraciones complejas, lo que facilita crecer al ritmo de la demanda. En sistemas alternativos, el escalado suele implicar mayor complejidad y limitaciones en el número de mensajes concurrentes. Kafka, en cambio, puede manejar millones de eventos por segundo manteniendo una baja latencia.
La resiliencia también es un factor diferenciador. La replicación de particiones en múltiples brokers garantiza tolerancia a fallos y continuidad de servicio incluso ante caídas de hardware. Además, el mecanismo de confirmación configurable (acks) ofrece flexibilidad para equilibrar velocidad y consistencia según las necesidades del negocio.
Otro punto fuerte es su integración nativa con ecosistemas Big Data y de procesamiento distribuido como Hadoop, Spark, Flink o sistemas de Machine Learning en streaming. Esto convierte a Kafka en un hub de datos que conecta aplicaciones, pipelines analíticos y sistemas de almacenamiento en un mismo flujo.
Finalmente, la simplicidad operativa es clave. Su diseño basado en logs segmentados reduce la fragmentación y simplifica la gestión del almacenamiento. Al unir durabilidad, rendimiento y escalabilidad, Apache Kafka es la opción preferida para arquitecturas modernas que requieren datos confiables en tiempo real.
¿Se utiliza Kafka en el aprendizaje automático?
La integración de Machine Learning con Apache Kafka transforma la gestión de datos en un sistema inteligente capaz de aprender y actuar en tiempo real. Kafka actúa como canal centralizado donde fluyen eventos, métricas y transacciones, mientras que los modelos de ML se conectan a estos flujos para generar predicciones inmediatas. Este enfoque elimina la fricción entre ingesta, procesamiento y acción, acelerando la toma de decisiones en escenarios críticos.
Un caso común es la detección de anomalías en sistemas industriales, ya que los sensores envían datos continuos a Kafka, que alimentan un modelo de ML entrenado para identificar desviaciones. Al detectar un fallo potencial, el sistema lanza alertas o incluso detiene procesos automáticamente. Otro ejemplo es la personalización en tiempo real en plataformas digitales. Cada clic del usuario pasa por Kafka y un modelo de recomendación analiza su historial para ajustar contenidos o sugerencias al instante.
Para implementar esta integración, frameworks como TensorFlow, PyTorch o Spark MLlib se conectan mediante conectores de Kafka Streams. Estos componentes permiten ejecutar inferencias directamente en el flujo de datos sin necesidad de almacenar ni reprocesar la información. Además, el soporte para microservicios facilita desplegar modelos como contenedores que escalan automáticamente según la carga de tráfico.
El valor real surge al combinar procesamiento en streaming con aprendizaje continuo. Kafka no solo alimenta modelos entrenados previamente, sino que también proporciona datasets históricos para reentrenar algoritmos y mejorar su precisión. Así, los sistemas evolucionan con el tiempo y se adaptan a nuevos patrones de comportamiento.
En definitiva, la unión de Machine Learning y Apache Kafka abre la puerta a arquitecturas proactivas, capaces de anticipar necesidades, reducir riesgos y ofrecer experiencias personalizadas de forma constante y fiable.
El dominio de Apache Kafka y su integración con Machine Learning es una habilidad estratégica en cualquier sector que trabaje con datos en tiempo real. La capacidad de diseñar arquitecturas distribuidas, optimizar pipelines de producción y aplicar modelos predictivos marca la diferencia entre una infraestructura básica y un ecosistema verdaderamente inteligente. No basta con entender la teoría, ya que se necesita experiencia práctica, uso de herramientas avanzadas y conocimiento profundo de los retos técnicos que surgen en entornos reales.
El Máster en Big Data & Business Intelligence ofrece la oportunidad de adquirir estas competencias de forma integral. A través de un enfoque práctico y aplicado, los alumnos trabajan con tecnologías de streaming, arquitecturas distribuidas y modelos de Machine Learning aplicados a casos de uso reales en la industria. Además, el programa incluye la guía de expertos internacionales y el acceso a proyectos profesionales donde se pone en práctica todo lo aprendido.
Formarte en este máster no solo abre puertas en empresas tecnológicas de primer nivel, sino que también te capacita para liderar la transformación digital en sectores como finanzas, telecomunicaciones, salud, retail o deporte. Es la vía más directa para convertir la teoría en resultados tangibles y situarte a la vanguardia del mercado laboral.