
Segmentación Semántica en Medicina
Las técnicas de visión por ordenador han supuesto una revolución en el campo de la inteligencia artificial. Las máquinas modernas son capaces de ver mejor que los humanos y determinar la naturaleza de aquello que están viendo. Las aplicaciones son casi infinitas y están solo limitadas por nuestra imaginación. La vista siempre ha sido nuestro sentido por excelencia y ahora las máquinas pueden ayudarnos a explotar el mundo mejor.
Segmentación Semántica en Medicina por ...

Como buen amante de la historia empezaré en los remotos años 90. Tras décadas de tímidos intentos por produccionalizar a gran escala sistemas de visión por ordenador se empiezan a ver las primeras aplicaciones para usos logísticos de lectura de caracteres. Para organismos como un banco o el departamento de correos, ser capaz de leer códigos de cheques o códigos postales era instrumental. Atrás quedaban los maravillosos inventos de principios del siglo XX en que se traducían caracteres a código telegráfico o tonos musicales o el nacimiento del OCD (Optical Character Recognition) en los años 70. Entrábamos en el siglo XXI y había que revolucionar el sector.
"Otra de las razones por las que la segmentación semántica está de rabiosa actualidad es la proliferación de librerías que nos permiten entrenar estos modelos sin apenas conocimientos informáticos"
Una de las primeras tareas que aprende un estudiante de computer vision es a clasificar imágenes. Empezamos con datasets simples con dígitos escritos y pequeñas redes neuronales que nos dicen si ese número que acabamos de escribir es un 1 o un 4. Pronto pasamos a clasificar imágenes de animales. ¿Es esto que veo un perro, un gato o un oso panda? La utilidad es enorme. No solo podemos digitalizar texto, podemos interpretar el mundo que tenemos alrededor. Podemos clasificar imágenes para ver si una extensión de tierra está cultivada, hay microfracturas en mis materiales de fabricación o el vino tiene el color adecuado para su fase de fermentación. No es ninguna sorpresa que a este proceso se le llama clasificación de imágenes.

Fig.1 Ejemplo del dataset MNIST
El siguiente paso era ser capaces de localizar entidades en una imagen. Ya no nos valía con clasificar la imagen, teníamos que determinar dónde estaba ocurriendo la acción y después clasificarla. Es muy útil por ejemplo en estimación de la pose donde queremos reconocer humanos antes de determinar dónde están sus articulaciones. ¿Pero por qué conformarnos con determinar una entidad? ¿Por qué no múltiples objetos en una imagen? Es el siguiente nivel de sofisticación en nuestro camino hacia la segmentación semántica. De una imagen podemos sacar muchas conclusiones como podemos ver en el siguiente ejemplo de DenseCap.

Fig 2. Análisis de un hombre a lomos de un elefante de DenseCap
¿Qué es la estimación de la pose? ¿Para qué se usa?
La Inteligencia Artificial es una ciencia muy multidisciplinar. Uno puede bucear en las a veces oscuras matemáticas de una red neuronal o calcular miles de probabilidades para construir un modelo. De las muchas opciones que tiene el usuario de inteligencia artificial hay una que sobresale: La de los Algoritmos pre-entrenados.
Hay una familia de algoritmos pre-entrenados increíblemente útiles para un gran número de aplicaciones relacionadas con nuestra posición corporal: La Estimación de la Pose
Ahora ya sabemos que está pasando en la imagen. Podemos clasificar múltiples entidades y saber que estamos viendo. Pero hay aplicaciones que necesitan precisión milimétrica, en las que necesito saber exactamente en qué pixel acaba un objeto y empieza otro. Esto es muy relevante para muchos sectores. Pongamos por ejemplo la conducción automática. No me basta saber que hay personas y coches en una imagen. Necesito saber dónde termina la acera y empieza la persona. Para ello tenemos algoritmos que clasifican todos y cada uno de los píxeles de una imagen y nos dicen a qué entidad hacen referencia.

Fig. 3 Segmentación semántica de la imagen captada por un coche autónomo
Para lograr esta maravilla de la técnica necesito varias cosas. La primera es una red neuronal potente con una arquitectura robusta capaz de segmentar la imagen en estos componentes. La segunda es una verdad base, una referencia de la que aprender. Estos algoritmos son supervisados y por tanto necesitan ser alimentados por ejemplos ya resueltos dados por expertos. Imaginemos un segmentador de mascotas en una imagen. Tenemos 3 clases: Mascota, borde y fondo. Podemos tomar imágenes segmentadas por humanos y entrenar nuestro modelo para hacer predicciones. Cuantos más datos, mejor aprenderá nuestra máquina.
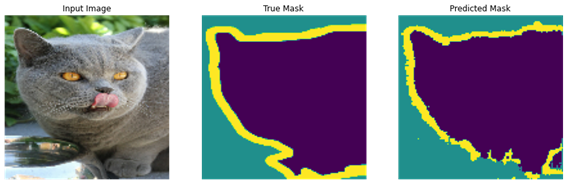 Fig.4 source: TensorFlow
Fig.4 source: TensorFlow
Vale, pero íbamos a hablar de medicina, ¿verdad?
Imagina las posibilidades. Las imágenes médicas son muchas veces muy difíciles de interpretar. Pongamos por ejemplo una mamografía. Una mamografía puede contener microcalcificaciones, pequeños clústeres de calcio de diferentes tamaños, formas, densidades, rugosidad, etc. Un buen oncólogo puede desarrollar una buena intuición para interpretar el impacto de estas microcalcificaciones a futuro. Pero solo con ayuda de una máquina será capaz de determinar si esas microcalcificaciones son una señal temprana de alarma de una paciente que puede acabar desarrollando cáncer de mama en los próximos 10 años. Determinar esto requiere un análisis píxel a píxel, muy concienzudo y muy preciso. Para entrenarlo hemos tenido que determinar qué mamografías pertenecían a clientes que acabaron desarrollando una patología. La mala noticia es que esta técnica no puede hacer nada por las pacientes del pasado, aquellas que generaron los datos históricos que ahora utilizamos. La buena noticia es que gracias al estudio de los patrones de sus mamografías podemos determinar rápidamente qué mamografías encierran una amenaza estudiando esos diminutos puntos blancos de calcio aparentemente inocuo.
Pues bien, esto es extrapolable a muchos más análisis. Podemos estudiar escáneres cerebrales para ver los patrones de consumo de glucosa y determinar si esos patrones representan un principio de Alzheimer. Podemos estudiar esos mismos escáneres para determinar si hay principio de tumores cerebrales.
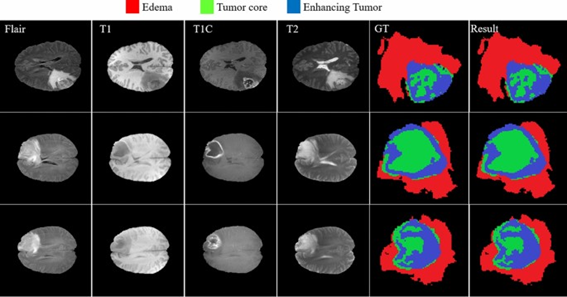
Fig. 5 Source: Nature
Igual que clasificábamos mascotas, ahora clasificamos tumores:

fig . 6 LGG Segmentation Dataset
Una vez más, las aplicaciones están aún por explotar. Estos últimos años se han multiplicado los estudios de afecciones pulmonares debido al impacto de la COVID-19 en la sociedad.
Otra de las razones por las que la segmentación semántica está de rabiosa actualidad es la proliferación de librerías que nos permiten entrenar estos modelos sin apenas conocimientos informáticos. Algunas muy especializadas en imágenes médicas y preparadas para obtener buenas conclusiones con pocos datos, ya que las imágenes médicas supervisadas son normalmente muy caras de obtener. Entre ellas destaca una de mis favoritas: Monai.
MONAI
Monai es un framework libre y open-source totalmente gratuito y basado en la popular librería de IA PyTorch. Provee capacidades muy optimizadas en el dominio de la medicina para desarrollar aplicaciones médicas basadas en imágenes en Python. No solo nos permite entrenar nuestros algoritmos, también provee de herramientas que ayudan a los investigadores y profesionales clínicos a etiquetar y clasificar imágenes y anotar datasets reduciendo los costes de aplicación enormemente. Monai es sin duda una herramienta que el mundo sanitario puede utilizar para obtener grandes beneficios para los pacientes.
¿Cuáles son las ventajas del uso de MONAI?
La ventaja del uso de MONAI para los especialistas en atención médica es que podrán usar herramientas de anotación asistidas por IA para automatizar la tarea manual y repetitiva de etiquetar imágenes médicas. Y este es un avance que debería generar más productividad en el día a día y salvar cada vez más vidas.
